FrameDiffuser
G-Buffer-Conditioned Diffusion for Neural Forward Frame Rendering
FrameDiffuser — Showcasing Image Diffusion is capable of autoregressive neural rendering.
Overview
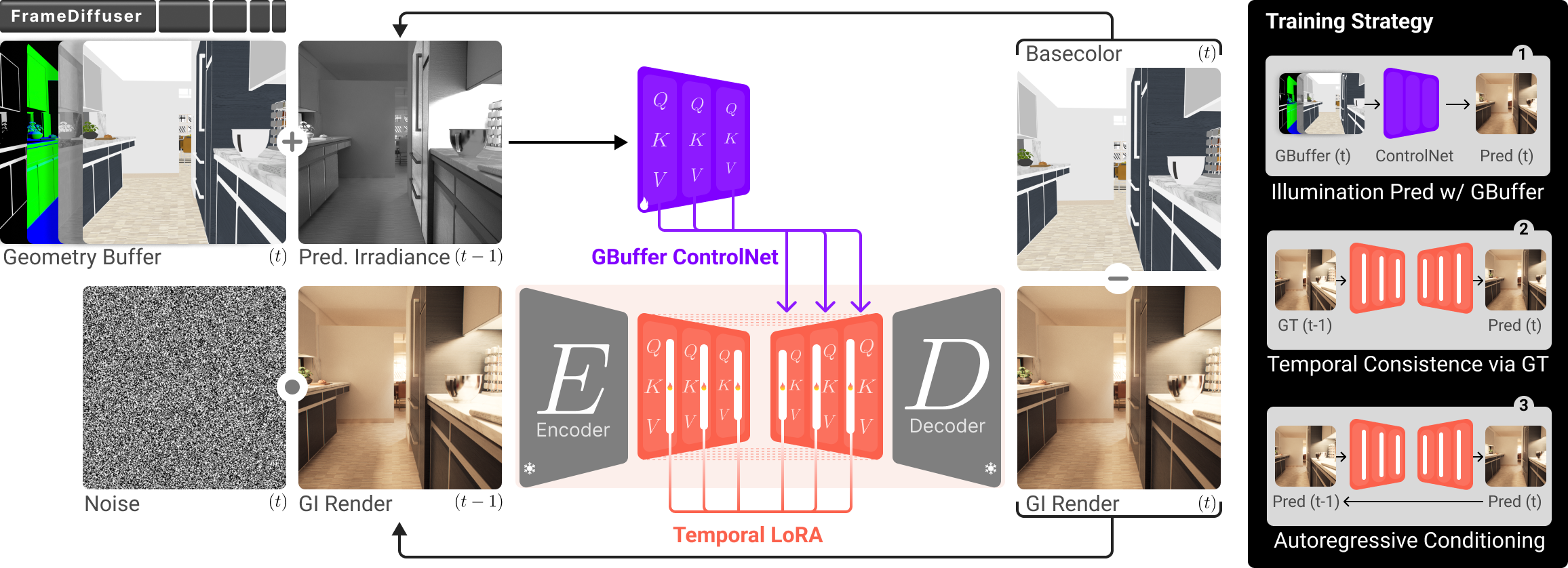
We propose FrameDiffuser, an autoregressive neural rendering framework that generates temporally consistent, photorealistic frames from G-buffer data. While single-image models like RGB↔X lack temporal consistency and video models like DiffusionRenderer require complete sequences upfront, our approach enables frame-by-frame generation for interactive applications where future frames depend on user input. After an initial frame, FrameDiffuser operates purely on incoming G-buffer data — geometry, materials, and surface properties — while using its previously generated frame for temporal guidance, maintaining stable generation over hundreds to thousands of frames with realistic lighting, shadows, and reflections.

Pipeline
Our dual-conditioning architecture combines ControlNet for structural guidance from G-buffer with ControlLoRA for temporal coherence from the previous frame. ControlNet processes a 10-channel input comprising basecolor, normals, depth, roughness, metallic, and an irradiance channel derived from the previous output. ControlLoRA conditions on the previous frame encoded in VAE latent space. Our three-stage training strategy — starting with black irradiance, introducing temporal conditioning, then self-conditioning — enables stable autoregressive generation without error accumulation.
Results
FrameDiffuser transforms G-buffer data into photorealistic rendering with accurate lighting, shadows, and reflections. We train environment-specific models for six different Unreal Engine 5 environments, demonstrating how specialization achieves superior consistency within specific domains. Our method achieves high visual quality while maintaining temporal consistency across extended sequences.
Hillside Sample Project
Downtown West
Electric Dreams
City Sample
X→RGB Comparison — Compared to X→RGB from RGB↔X, our method achieves more realistic lighting with high-detail illumination while maintaining temporal consistency across frames over long sequences. X→RGB produces images that appear artificially flat with uniform lighting, lacking the rich lighting variation, shadow depth, and atmospheric effects present in photorealistic rendering.

DiffusionRenderer Comparison — Unlike DiffusionRenderer, which requires complete sequences upfront and is limited to 24 frames, our autoregressive approach enables frame-by-frame generation for interactive applications. On comparable 24-frame sequences, FrameDiffuser maintains superior temporal coherence and produces more nuanced illumination with realistic shadows and atmospheric depth, while DiffusionRenderer's batch processing results in less natural lighting transitions.
Scene Editing — When objects are added to the scene through G-buffer modifications, FrameDiffuser automatically synthesizes appropriate lighting, shading, and cast shadows. This enables artists to maintain full control over scene composition while FrameDiffuser handles the computationally expensive lighting synthesis automatically.

Limitations
Our environment specific approach prioritizes consistency over generalization, requiring separate models for different visual styles. We show a few examples of the model's ability to handle different visual styles in the following section. The biggest current limitation is the baseline model and its decoder.
VAE Flicker — The VAE of Stable Diffusion 1.5 introduces temporal flicker, especially in scenes with high spatial frequencies like metropolitan cityscapes. When comparing to pure VAE reconstruction, this flicker becomes apparent in generated sequences. We believe that with a different VAE—such as finetuned VAE decoders or VAEs incorporating previous frame context—this flicker could be substantially reduced or eliminated. However, training or fine-tuning a specialized VAE requires significant computational resources and falls outside the scope of this work, which focuses on the frame generation pipeline itself.
Future Work
Future work could combine video diffusion architectures like FramePack with our G-buffer conditioning approach, or explore integration with recent 3D scene generation and reconstruction methods, merging DiffusionRenderer's temporal modeling strengths with interactive generation requirements. Further, experimenting whether world knowledge capabilities like changing scene style via prompting remain accessible. We also explore the inverse of prediciting GBuffer from a scene. We tested a few examples, however all of this can be improved in future work.
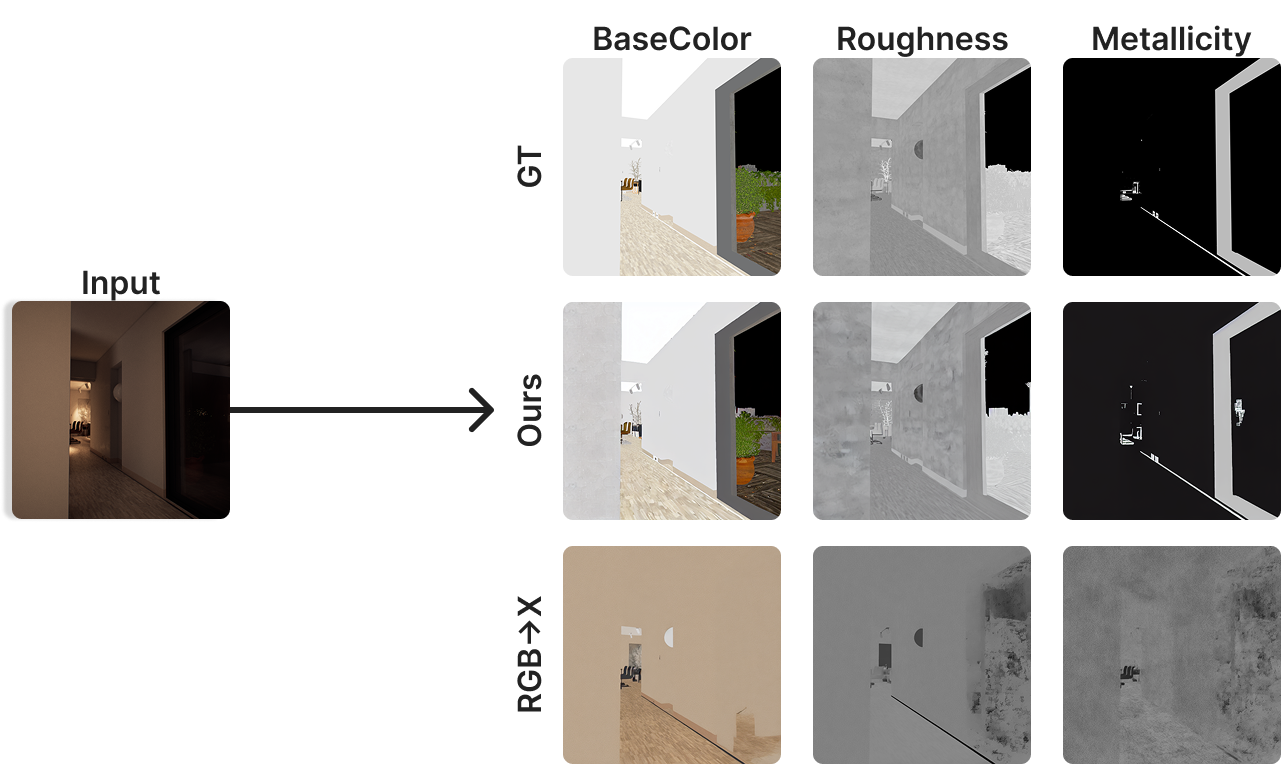
GBufferDiffuser: Inverse Rendering — While forward rendering (G-buffer to RGB) is the main focus of this work, we also developed GBufferDiffuser for inverse rendering (RGB to G-buffer), similar to RGB↔X. This system employs five independent ControlLoRA models, each specialized for reconstructing a specific G-buffer component: basecolor, depth, normals, roughness, and metallic. In contrast to generalist approaches that train a single model across multiple G-buffer types and environments, we train smaller specialized adapters for each component on a single environment. This specialization approach allows for faster training while achieving superior results within the target domain, substantially outperforming generalist baselines across all G-buffer components.
Style Transfer — We explored artistic control through style transfer by applying first-frame augmentation. Given an original rendered frame, we apply Stable Diffusion's image-to-image transformation with a style-specific text prompt to create a stylized version. This stylized frame then serves as the previous frame input for the first generated frame, and generation continues autoregressively. The experiments revealed limited style transfer capabilities due to the model's specialization on training environments with fixed prompts. After training on a single prompt-environment combination, the model's ability to respond to alternative text conditioning decreased.
Citation
More Information
Open Positions
Interested in persuing a PhD in computer graphics?
Never miss an update
Join us on Twitter / X for the latest updates of our research group and more.
Recent Work
Acknowledgements
Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy – EXC number 2064/1 – Project number 390727645. This work was supported by the German Research Foundation (DFG): SFB 1233, Robust Vision: Inference Principles and Neural Mechanisms, TP 02, project number: 276693517. This work was supported by the Tübingen AI Center. The authors thank the International Max Planck Research School for Intelligent Systems (IMPRS-IS) for supporting Jan-Niklas Dihlmann.